KEDA
For years, developers have been facing the problem of scaling their architecture/workflow. Cloud containers have proved to be a sign of relief for all the developers, but some problems are persistent. A lot of companies/developers have to follow the concept of event-driven architecture, thus as the work is alloted the work should be done in the same fashion, only the major timeline is decided and not the whole workflow.
While using Azure, one can stack up the work and while scaling it Azure automatically does it with you having no control over it, HPA ( Horizontal Pod Autoscaler) from Kubernetes does give you the flexibility to scale the workflow but while working with event based architecture if there are multiple sub-pods working on the multiple sub-messages then without the knowledge of which pod is actually busy, based on the time the pods gets terminated during the scale down process. This process of terminating the pods creates a void of time where we need to re-insert the remaining job and thus adding up to the time taken up by the job to complete, resulting in work for hours.
All these issues could have been solved by a hack of using the concept of prepStophook or using Kubernetes Job but both of t)hem were tricky to implement for a beginner. This is where KEDA comes in.
What is KEDA ?
| Image Credits : Kedacore Github images |
Looking at all the persisting problems Microsoft and Red Hat formed a collaboration in May,2019 to come up with a solution KEDA i.e. Kubernetes-based Event Driven Autoscaler. With KEDA, the developer can control the scaling of the container based on the number of events needing to be processed. KEDA is a lightweight and single purpose component that aligns its functionality with all the other functionality of Kubernetes running on the same system.
KEDA is an official CCNF project and as of is currently a part of CCNF Sandbox. It is built on the top of Kubernates Horizontal Pod Autoscaler(HPA) and thus allows the users to take advantage of external connections to applications such as Apache Kafka, Azure Queue, MongoDB Database, Huawei CloudEye etc.
Features of KEDA

How does KEDA work ?
KEDA works on three different components:
- Scaler: It is a Kubernetes tool that allows users to track nodes inside the cluster, attach the cluster to the external sources(eg: Apache Kafka, MYSQL) and fetch metrics from it. It is defined by the ScaleObject(Custom Resource) manifest.
- Operator: Also know as the Kubernetes cluster agent, it helps to activate the deploy and create the HPA object
- Metrics Adaptor: It helps to analyze and present the metric to HPA. To be more precise it helps to fetch the correct metricx from the Kubernetes external metric and convert it in the form that can be understood by the HPA
The given below images shows the working on KEDA in conjucntion with Kubernetes HPA and external scalers
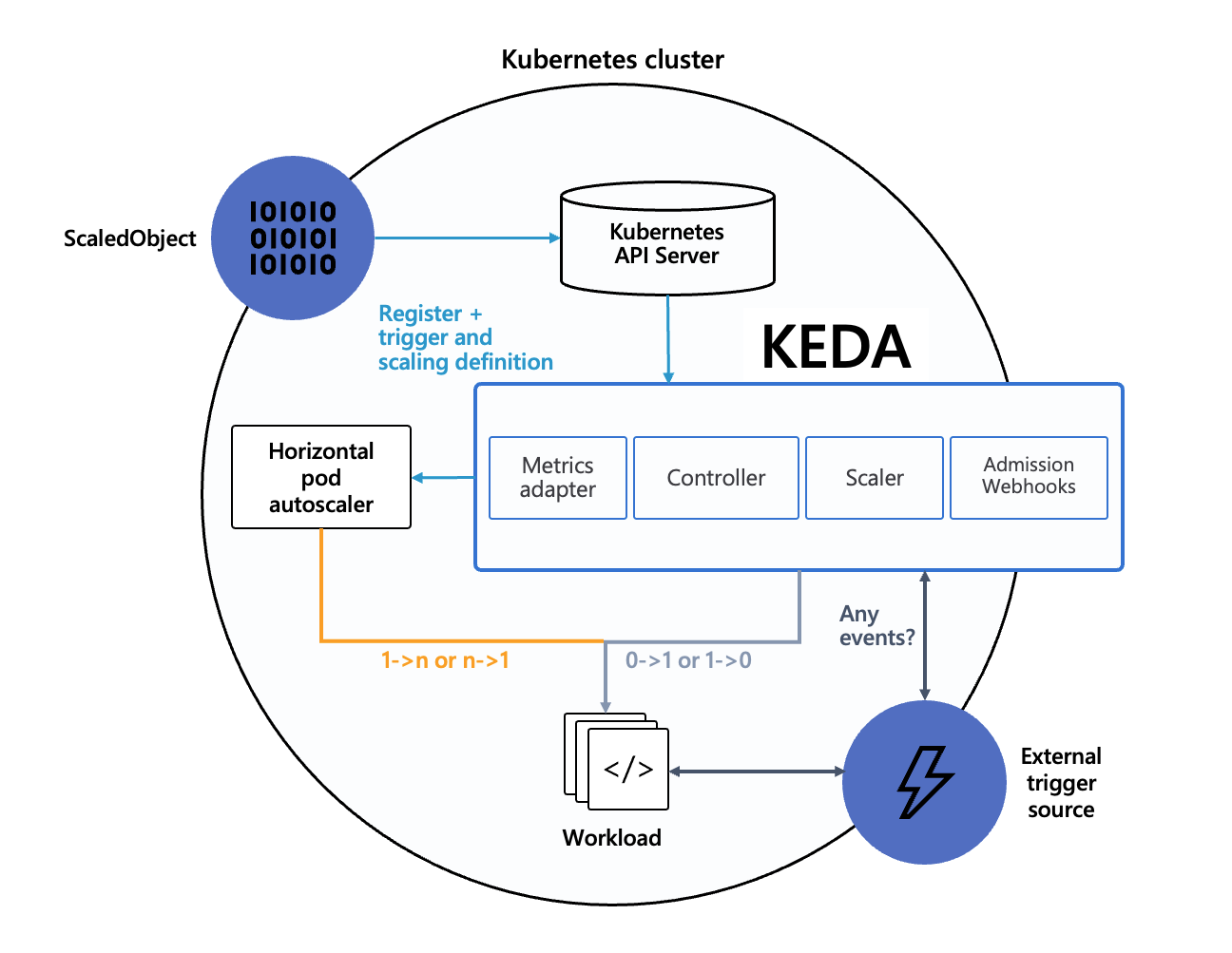 |
|:--:|
|Image Credits : KEDA official site|
|
|:--:|
|Image Credits : KEDA official site|
To deploy KEDA runtime in your Kubernetes cluster through :
While downloading KEDA in your kubernetes cluster, ensure that KEDAv1 and KEDAv2 are not running on the same machine and ensure that you download the latest version of the API, scalers and triggers for the respective version
When you install KEDA it install four custom resources:
- scaleobjects.keda.sh : This represents the desired mapping/relation between the scaler and the job/deployment at the Kubernetes cluster.
- scalejobs.keda.sh : This represents the relations between the kubernetes job and the event source.
- triggerauthentications.keda.shggerauthentications.keda.sh)
- clustertriggerauthentications.keda.sh
Trigger authentications and Cluster trigger authentication contains the authentication details to the event source and deployment container
After installing KEDA in your Kubernetes cluster, this is how you can typically use KEDA for the efficient development of the project/work:
- Create a Job/Deployment which is simply an application you want KEDA to scale based on the information embedded in your scale trigger. Apart from that it is completely independent.
- Create a ScaleObject which is Custom Resource Definition that helps to define the source of the metrics and also helps autoscaling criterias.
Once these processes are done Kubernetes is set into motion for collecting all the needed information from the event source and drives the autoscaling immediately.
How to contribute to KEDA ?
KEDA accepts contributions in the form of coding, documentation, issue triage, sample, content and much more. KEDA gives you an opportunity to be the part of its mission through various methods
Wait for no time to join in the crusade of development.
Conclusion
KEDA is lightweight and flexible and thus it can deployed with any Kubernetes cluster to add to the efficiency of its functionality. It can handle from traditional workloads to serverless functions. KEDA will ensure that however long your job is running it is scaled down to zero instances,before it is terminated. And above, it can be integrated with custom event sources in form of scalers to drive an efficient autoscaling process